Crear un recomendador de productos: Amazon Personalize

Esta vez investigando alguna herramienta para recomendación de productos en mi trabajo, me encontré con Personalize (Amazon Personalize), poderosa pero ¿Simple?. Veamos!
A continuación una guía de cómo dar tus primeros pasos.
¿Qué es Amazon Personalize?
Según AWS
Amazon Personalize es un servicio administrado (fully managed) de Machine Learning que hace "fácil" a los desarrolladores presentar experiencias personalizadas a sus usuarios, y refleja el conocimiento y la experiencia que tiene Amazon al momento de construir sistemas de personalización.
https://docs.aws.amazon.com/personalize/latest/dg/what-is-personalize.html
El producto final
El objetivo de esta guía es que puedas conocer los fundamentos de Amazon Personalize, el resultado final será una recomendación de productos específicos para cada uno de los clientes de nuestro sitio.
Materiales
En este caso nos vamos a focalizar en generar un "recommender"para recomendar productos a nuestros usuarios
- Tiempo requerido para este laboratorio: 1 - 2 horas.
- Una cuenta de AWS (Si no tienes cuenta, debes crear una: https://portal.aws.amazon.com/billing/signup#/start/email)
- Lo que vamos a utilizar cuesta aproximadamente aprox USD 2 si ya no tienes free tier disponible.
- Un bucket de S3 para poder subir los archivos de datos.
- Datasets (archivos CSV con información)
- Nivel Padawan (aprendiz): Interacciones de los usuarios con tus productos
- Nivel Jedi (Intermedio): Interacciones + Productos con atributos
- Nivel Yoda (Avanzado): Interacciones + Productos con atributos + Usuarios
Preparación
Creación del Bucket de S3
(si ya tienes un bucket de S3 para guardar información, pasa a la sección de configuración adicional del bucket para Amazon Personalize)
En la consola de AWS buscamos S3 en el buscador de servicios que se presenta arriba a la izquierda.
Luego vamos a "Buckets" - Create Bucket
Elegimos un nombre representativo para el Bucket:
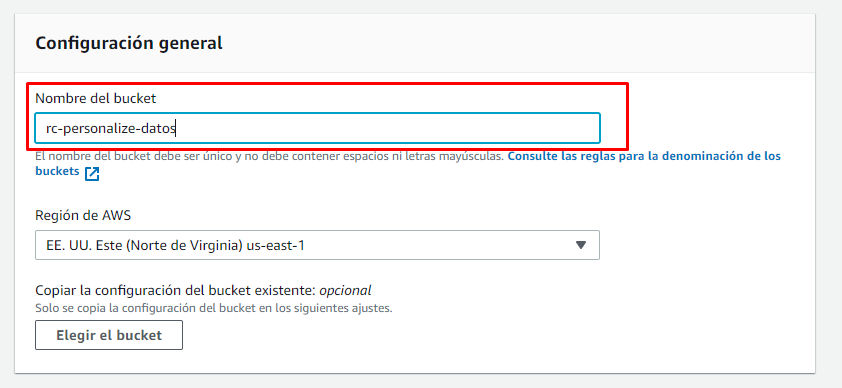
A los fines de este paso a paso dejamos los valores del formulario por defecto, pero sugiero en caso de quere pasar a producción el trabajo evaluar si hay algún requisito adicional necesario en lo que respecta a copia de seguridad, versionado y cifrado de la información.
Presionamos: Crear Bucket

Configuración adicional del Bucket para Amazon Personalize
Es requerido que el Bucket de S3 permita el acceso desde el servicio de Amazon Personalize para poder leer los archivos que hay dentro del bucket.
Desde el listado de Buckets clickeamos sobre el bucket recién creado

En la siguiente pantalla nos vamos a donde dice "Permisos"
En la sección Política del bucket, clickeamos "Editar"
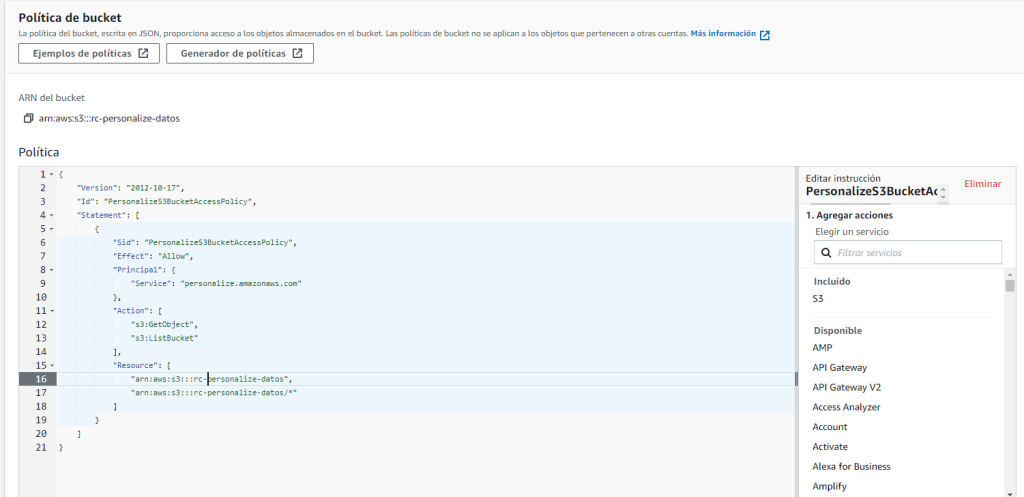
Allí, en caso de ser este un bucket nuevo, eliminamos el valor por defecto y copiamos y pegamos el siguiente JSON reemplazando bucket-name por el nombre de nuestro bucket.
Si no es un bucket nuevo y tiene alguna politica adjunta, agregar los permisos requeridos (Effect, Pricipal, Action y Resource) a la política actual.
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}
Deberá quedar así:
Preparar los archivos de datos: (Datasets)
Asegúrate de tener archivos CSV preparados con las siguientes estructuras
Interacciones
Es recomendable que este CSV tenga al menos 1000 registros del tipo "View" para sacar provecho de las diferentes "recetas"que hay para recomendar productos.
Es importante que aquí haya eventos solo "Positivos" Amazon Personalize no reconoce eventos "Negativos", ejemplo: Eliminar un producto del carrito, para Amazon Personalize no es significativo.
Los eventos que AWS Personalize indica que debemos registrar son los: View y los Purchase
Es importante respetar el nombre de las columnas requeridas y opcionales.
Se pueden agregar hasta 5 columnas adicionales de metadata que combinadas con los diferent event types no superen las 10 columnas respetando los formatos establecidos: https://docs.aws.amazon.com/personalize/latest/dg/how-it-works-dataset-schema.html#personalize-datatypes
Si alguna de las columnas es del tipo CATEGORICAL y contiene más de un valor, separar las columnas con pipes "|"
Columnas Requeridas
- USER_ID (string)
- ITEM_ID (string)
- TIMESTAMP (long)
- EVENT_TYPE (string, (Purchase, View))
Columnas Opcionales
- EVENT_VALUE (float), por si queremos darle más peso a un evento
- IMPRESSION (string), aca podemos pasar que conjunto de productos se presentaron al usuario cuando interactuó con el producto que estamos enviando (Más info: https://docs.aws.amazon.com/personalize/latest/dg/interactions-datasets.html#interactions-impressions-data)
- RECOMMENDATION_ID (string)
Items (Productos con atributos)
Este dataset es opcional, pero te lo recomiendo si queres obtener recomendaciones más acordes a tus usuarios.
Columnas Requeridas
- ITEM_ID (string)
- PRICE (float)
- CATEGORY_L1
Columnas Opcionales
- CATEGORY_L2 (string)
- CATEGORY_L3 (string)
- PRODUCT_DESCRIPTION (textual)
- CREATION_TIMESTAMP (float)
- AGE_GROUP (categorical, string)
- ADULT (categorical, string): Yes, No
- GENDER (categorical, string): Male, Female, Unisex
Usuarios
Este dataset también es opcional, pero como mencione anteriormente, cuanto más especificas quieras las recomendaciones y más información le des al sistema, mejor.
En este dataset debemos volcar la información que nos parezca relevante de los usuarios, el ID, si tenemos algún loyalty program el nivel en el que se encuentran (Bronze, Gold, Platinum, Diamond, o el nombre que le hayamos dado), la edad, género, o por ejemplo que tipos de series le gustan.
Columnas Requeridas
- USER_ID
- Algun metafield (Ejemplo Loyalty_program, age, gender)
Subir los Datasets al Bucket de S3
Estos 3 Datasets (recuerda que el único obligatorio es el de interactions) los debemos subir al Bucket de S3 creado al principio.
Dentro del Bucket presionamos: Cargar
Agregar Archivos
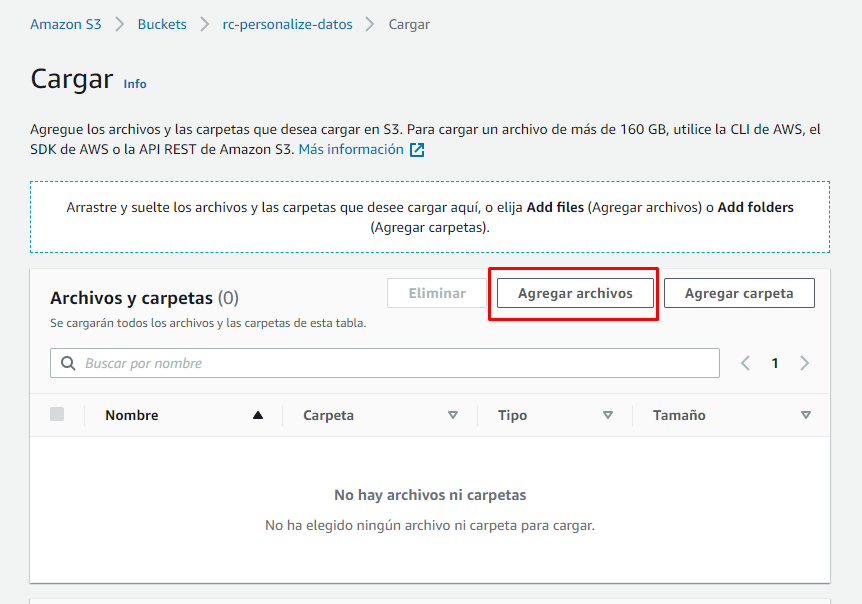
Luego elegimos en nuestra carpeta local los archivos que queremos subir y presionamos "Cargar"
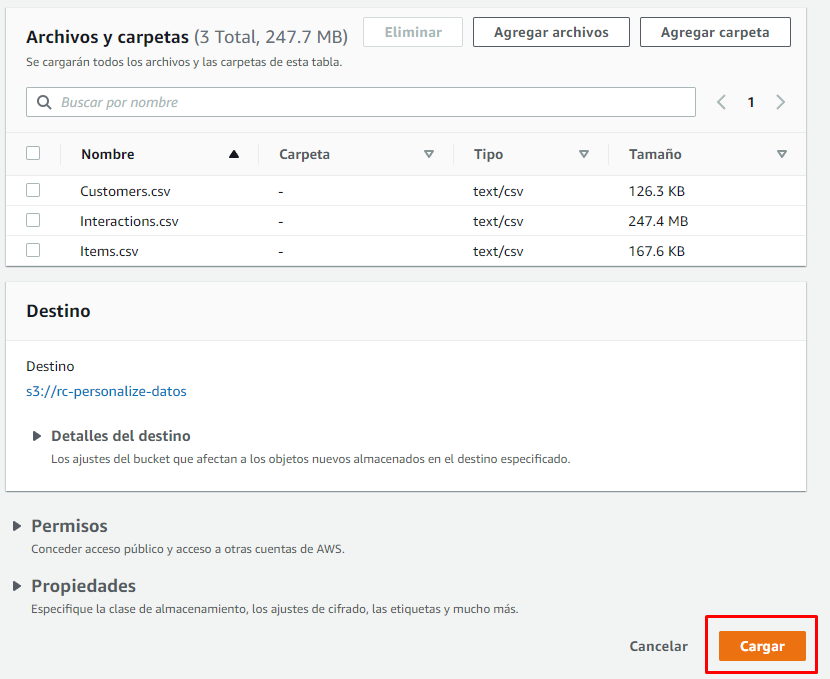
Una vez terminada la carga, presionamos "Cerrar"
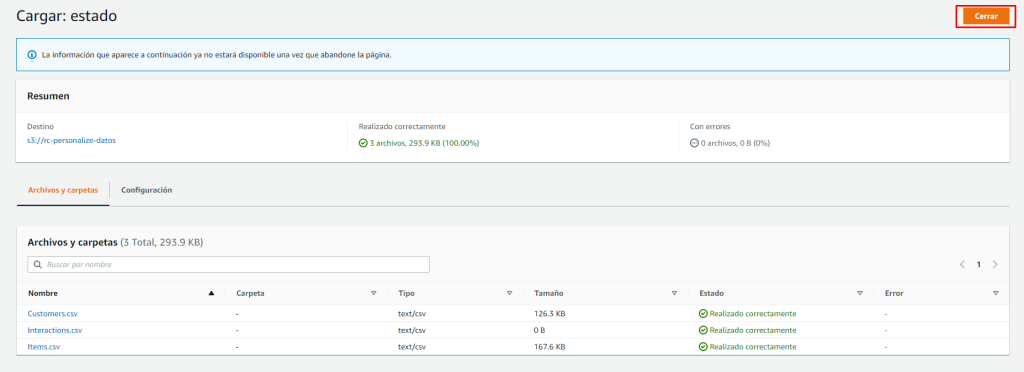
Paso a paso
Suponiendo que ya tienes los datasets creados, los pasos a seguir son los siguientes:
- En la consola de AWS buscamos Amazon Personalize
Crear Dataset Group
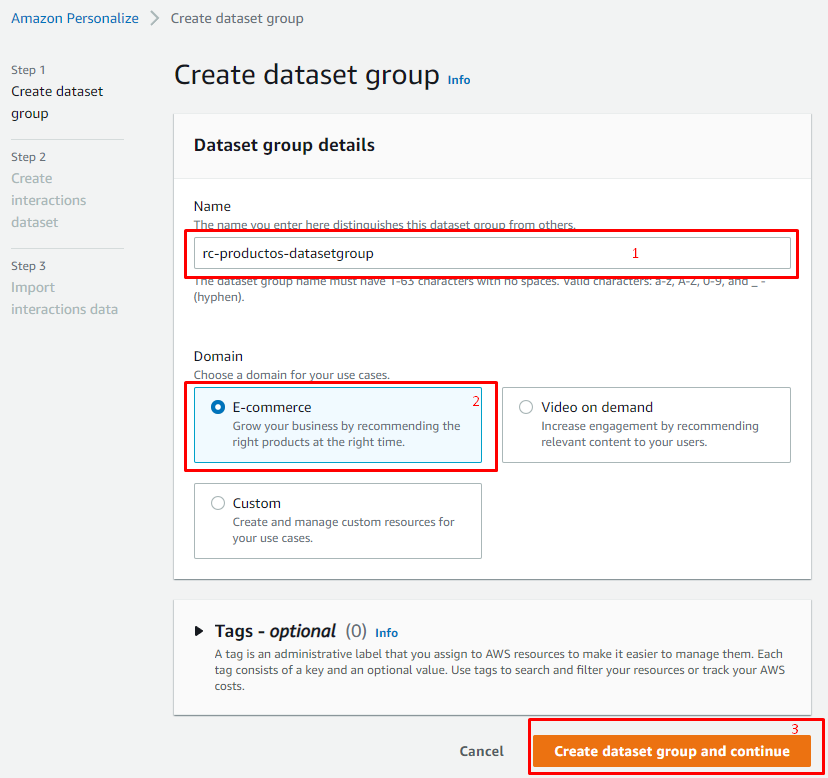
- Dentro de Amazon Personalize nos vamos a donde dice Create Dataset Group

Un datasetgroup es un "Agrupador de información", aquí es donde agruparemos los distintos contenidos para recomendar, por ejemplo podemos tener un dataset group para recomendar libros, otro para recomendar videos, otro para recomendar ropa.
Le asignamos un nombre, y en seleccionamos el tipo de "Dominio" para los casos de uso, en este caso vamos a seleccionar Ecommerce, dado que estamos buscando recomendar productos.
Crear el primer dataset en Amazon Personalize
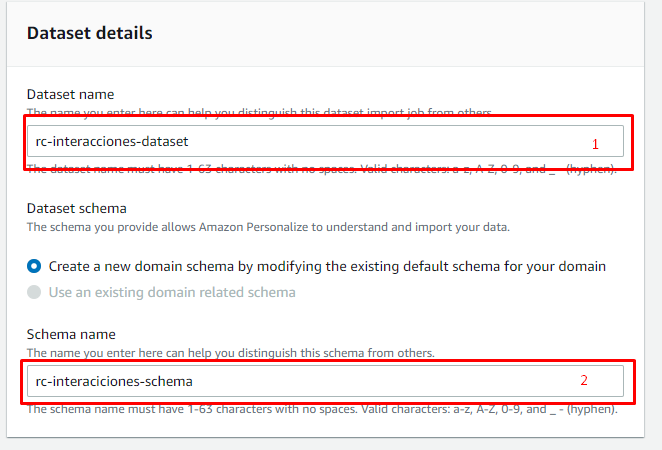
Ahora crearemos nuestro primer dataset, en este caso el de interacciones, un dataset es justamente la información que vamos a cargar, le ponemos un nombre al dataset de interacciones y un nombre al schema.
Definir el Schema
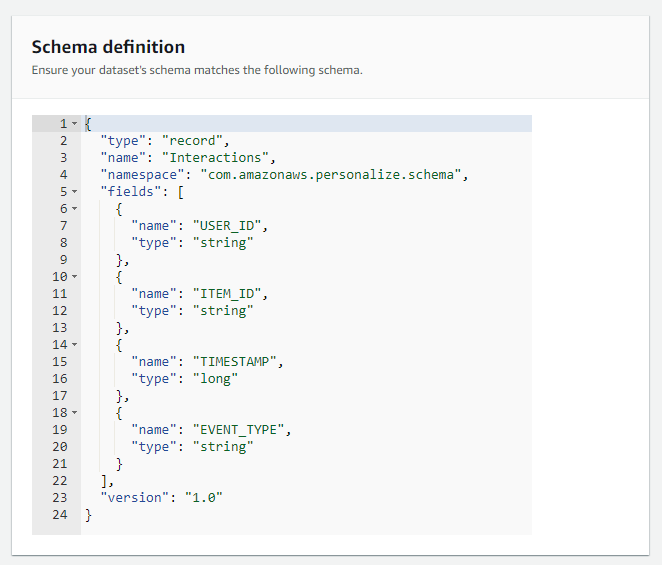
En este caso podemos dejar el schema por defecto dado que es el que vamos a estar utilizando en nuestro sistema, pero si gustamos debemos hacer las modificaciones que deseemos aqui.
Tipos de datos para los Schemas
Esta es una lista de los diferentes tipos soportados por AWS Personalize para los schemas:
| Tipo | JSON |
|---|---|
| float | { |
| double | { |
| int | { |
| long | { |
| string | { |
| boolean (true o false) | { |
| null (Si queremos indicar que algun valor puede ser nulo, debemos incluirlo al momento de la definición) | { |
Cuando un campo es del tipo Categorical, debe aclararse al momento de definir el schema (en el caso del dataset de interactions, no tenemos ningun tipo categorical, pero probablemente en el dataset de usuarios o productos lo tendremos
{
"name":"GENRES",
"type":"string",
"categorical":true
}
Importar el Dataset (Crear un import job) en Amazon Personalize
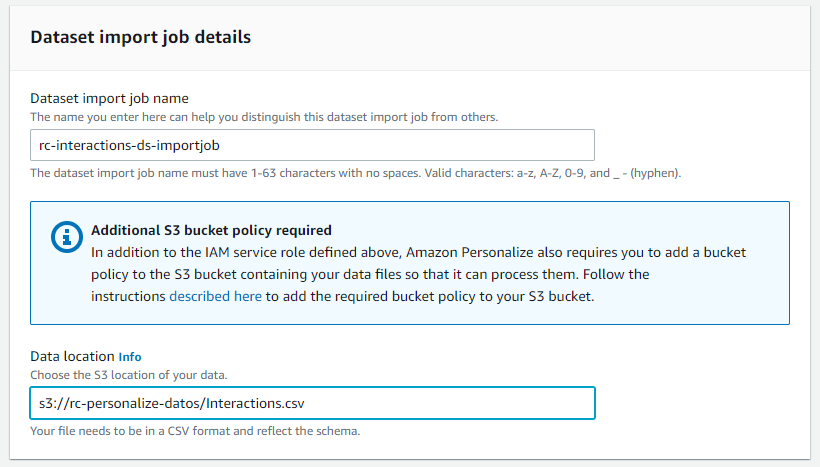
El paso siguiente es importar los datos, para esto Personalize nos solicita crear un import job, cada vez que querramos importar nuevos datos, debemos crear un Import Job.
Aquí le definimos un nombre a nuestro import job y escribimos la ubicación del archivo CSV con las interacciones de los usuarios. Recuerda que el Bucket tiene que tener la policy que creamos en el apartado "Preparación", sino no va a funcionar
A continuación nos solicita que le indiquemos cuál es el Rol que puede acceder a el bucket de S3 creado anteriormente, este rol debe tener la política AmazonPersonalizeFullAccess.
En mi caso no tengo este rol creado, por lo que voy a elegir 'Create a new role' y Amazon Personalize lo hará por mí.
Luego indicamos a que Bucket / Buckets tendrá acceso este rol.
Podemos escribir el nombre de nuestro Bucket, en mi caso es redundante dado que el Bucket ya contiene el nombre personalize dentro de él (rc-personalize-datos), por ende al utilizar el wizard de AWS está creando un rol para todos los buckets que contengan el nombre Personalize
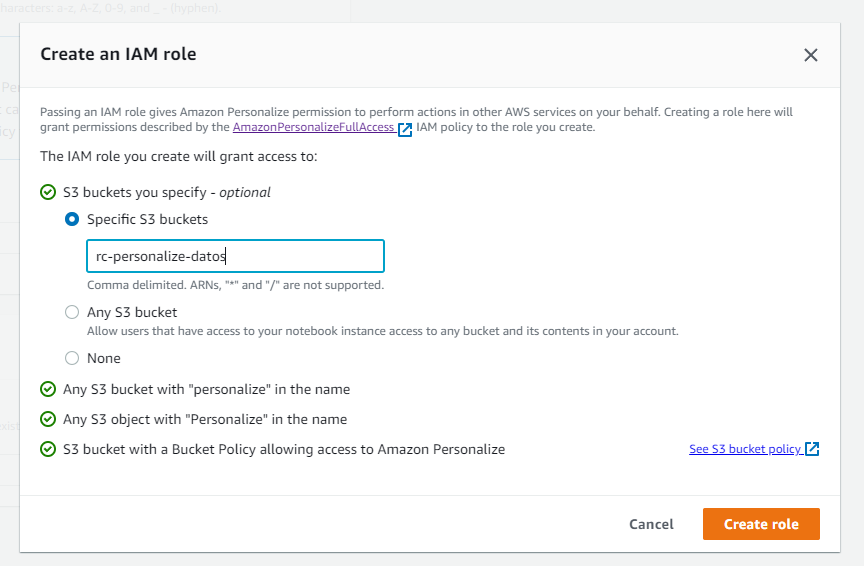
Presionamos Create Role y ya tendremos nuestro Rol creado.
En la ventana original presionamos: Create dataset import job
Si todo sale bien, comenzara la importación del dataset.
Si clickeamos en "Overview" dentro de Amazon Personalize, podremos observar que la importación del dataset de interactions está en curso, en mi caso fueron 250Mb de datos, y tardó en procesarse aproximadamente 3 minutos.
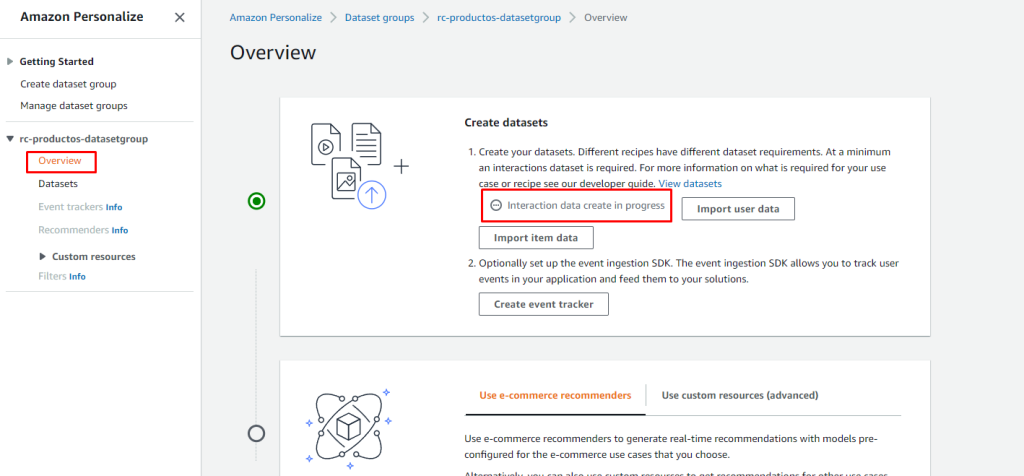
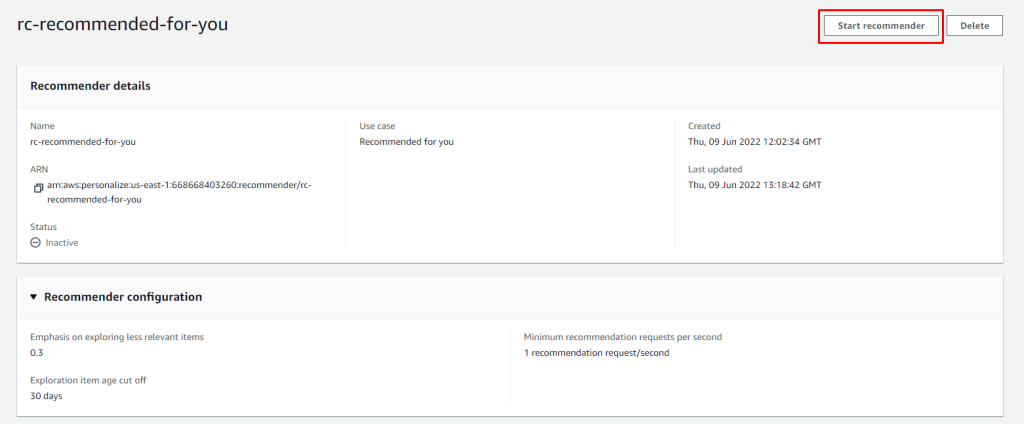
Crear el Recomendador
Una vez que ya nos aparece "Active" el dataset de interactions, se nos habilita el siguiente paso para comenzar a crear los "Recommenders", en la pantalla de Overview presionamos "Create Recommenders"
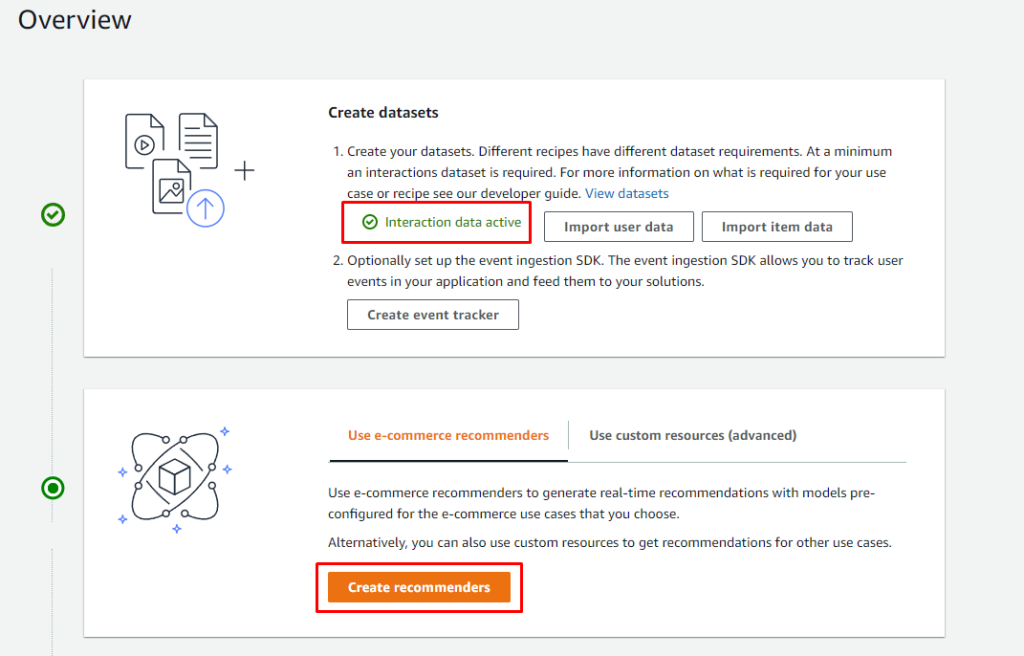
Aquí AWS Personalize nos muestra las diferentes opciones de recomendadores que podemos crear (son las recetas/casos de uso), aquí debemos tener especial cuidado con las recetas que utilizamos dado que se nos cobrará por cada receta que decidamos crear y cada recomendador activo que tengamos. (Ver Explicación de Precios)
En nuestro caso vamos a elegir el caso de uso: Recommended for you
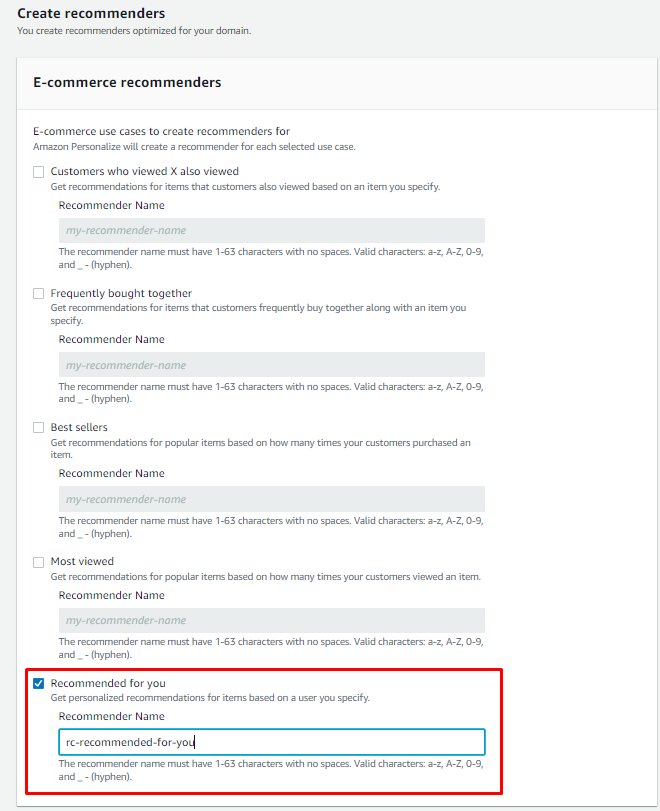
Aquí un detalle de los casos de uso:
| Caso de uso | Input | Output |
|---|---|---|
| Customers who viewed X also viewed | Item ID | Listado de items que otros customers vieron luego de ver el que pasamos como input |
| Frequently Bought Together | Item ID | Listado de items que otros customers frecuentemente compraron junto a este. |
| Best Sellers | User_ID | De acuerdo a los items que compró el usuario devuelve un listado de otros items que mejor se vendieron |
| Most Viewed | User_ID | Basado en las veces que el Customer vio un item, trae items recomendados para ver |
| Recommended for you | User_ID | Devuelve items que son recomendados para el usuario. |
Amazon Personalize luego nos da la opción de configurar de manera avanzada este recomendador (o los que hayamos seleccionado)
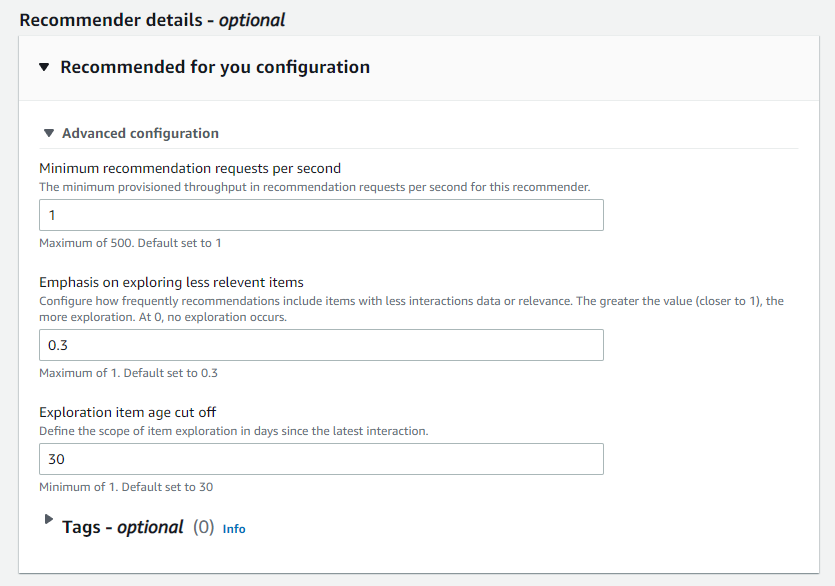
En este caso:
Minimum recommendation requests per second: Este parámetro es muy importante dado que aqui debemos especificar cuantas veces por segundo vamos a utilizar el recomendador y amazon nos cobra por la cantida de horas/recomendaciones generadas, si nos excedemos de esta cantidad, Amazon Personalize auto escalará para poder satisfacer los requests, y luego cuando la demanda baje, volverá a lo que configuremos aquí, pero nunca menos.
En este caso podremos realizar un request por segundo, lo que nos indica 60 requests por minuto, son 3.600 requests por hora. Recomiendo dejarlo en 1 si no sabemos la cantidad de requests minimos e ir ajustando este parámetro.
Emphasis on exploring less relevent items: El sistema para poder recomendar generalmente empieza con los items con mayores interacciones, dado que asume que estos son los más claros, pero también se sugiere dejar un margen para "Explorar", aqui es un valor que va de 0 a 1, en este caso por ejemplo 0.3 significa que el 30% de los items recomendados podrán ser exploratorios, es deecir que se usarán para experimentar. (Supongamos que recomendamos de a 4 items, 1.2 items podrian ser exploratorios). (Para que esto funcione bien, se recomienda subir un dataset de interactions nuevo periódicamente, o utilizar un Event Tracker. (https://docs.aws.amazon.com/personalize/latest/dg/recording-events.html)
Exploration item age cut off: En caso que deseemos explorar, lo que va a hacer el sistema es no utilizar para las recomendaciones items que no hayan tenido interacciones en los últimos días especificados en este parámetro, en nuestro caso no recomendará items que no hayan tenido interacciones en los últimos 30 días.
Presionamos: Create Recommenders

El Recommender pasará a crearse, este proceso demora aproximadamente 60 minutos
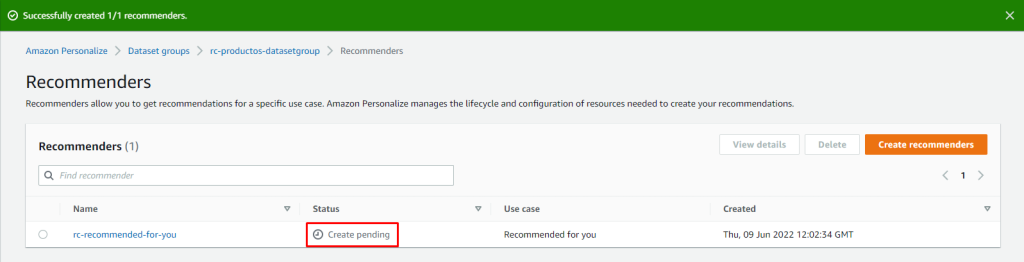
Evaluando el recomendador creado
Hay dos maneras de evaluar las recomendaciones de Amazon Personalize, una y la más recomendable es la denominada "online", es aquella que se mide en base a los clicks que hicieron los usuarios a los productos recomendados por Amazon Personalize.
La segunda, es en base a las métricas que arroja Amazon Personalize al momento de crear el recomendador.
Una vez finalizada la creación del Recommender, vemos que nos devuelve métricas en base a lo que pudo entrenar el sistema y las recomendaciones que arrojará.
Estas métricas se generan de la siguiente manera:
El sistema toma el 10% como muestra para testeo.
Se utiliza el dataset para entrenar el modelo.
Luego se le pasa el 90% de la data más vieja como parámetro al modelo y trata de predecir el 10% que luego es comparado con la data de testeo.
A modo de resumen estos valores van de 0 a 1, cuando más cerca del 1, mejor.
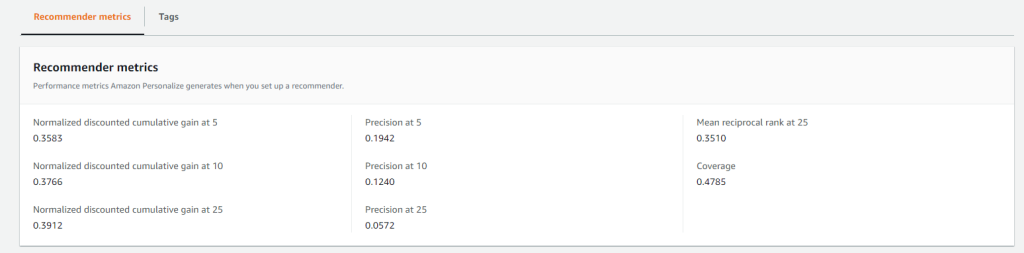
| Métrica | Descripción |
|---|---|
| Coverage | Cuántos items diferentes recomienda el sistema sin entrar a repetir el mismo item. Si utilizamos exploración es probable que este número sea más alto |
| Mean Reciprocal Rank at 25 | Esta medida nos sirve para evaluar la precisión del recomendador para acertar el Top 1 recomendado. |
| Normalized Discounted Cumulative Gain at (5,10,25) | Este valor nos indica para el Top 5,10,25 el grado de relevancia de los resultados, penalizando los resultados que el sistema consideró relevantes pero en el testing aparecieron en ubicaciones más abajo, es decir aqui se premian los resultados relevantes que aparecieron arriba en las listas. |
| Precision at 5,10,25 | Esta métrica nos indica la relevancia de los resultados en un Top 5,10 y 25, en este caso en vez de considerar la relevancia de los resultados, se considera la precisión de la recomendacion de los elementos relevantes. |
Probando el recomendador
En la pantalla principal del recomendador nos vamos a "Test Recommender"
Luego nos solicitará ingresar el parámetro User ID:
Ingresamos algun usuario de nuestra base de datos:
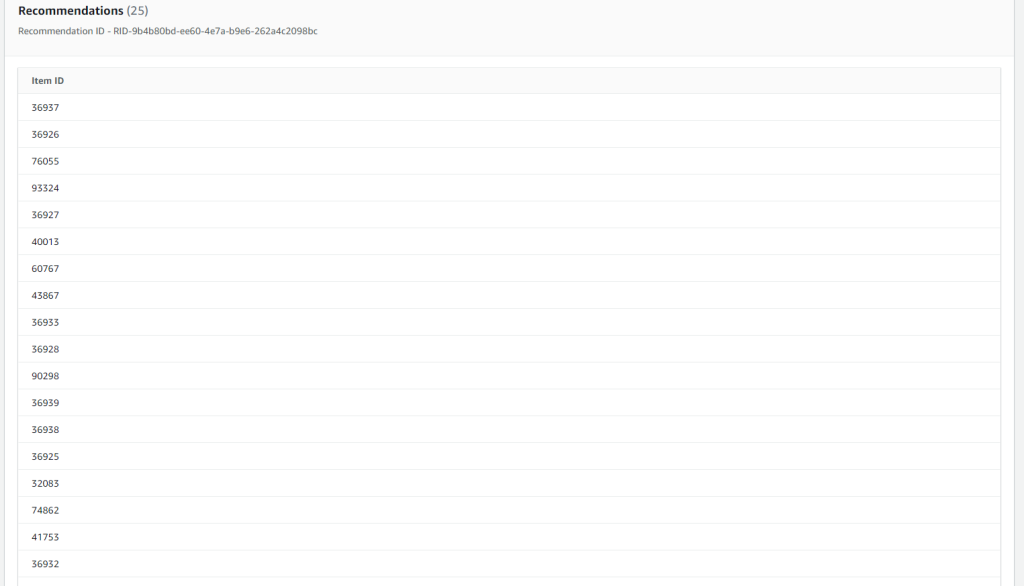
A continuacion nos mostrará 25 recomendaciones para este usuario:
¿Cómo seguir?
A continuación queda a nuestro criterio como continuar, por ejemplo podemos:
- Crear un script en nuestro lenguaje de programación favorito que consulte la API de Recomendaciones
- Utilizar recomendaciones en Batch para crear campañas específicas
- Implementar un Event Tracker para ir optimizando el recomendador
En próximas entregas abordaré los ejemplos anteriormente citados e iré actualizando los links.
Explicación de los costos
Los precios se encuentran en el siguiente link: https://aws.amazon.com/es/personalize/pricing/
Dado que a veces cuesta entender el pricing, voy a tratar de hacerlo más sencillo
Amazon cobra por:
- Ingesta de datos (proceso de los datasets + store de los datasets en S3)
- Por hora que el recommender esté ejecutandose y cada 100.000 usuarios (hasta 4000 recomendaciones por hora) y escalando en recomendaciones por hora en base a la cantidad de usuarios. (un usuario es un USER_ID dentro del dataset de interacciones y de usuarios).
- Si excedemos las 4000 recomendaciones por hora (o las que vengan incluidas en cada hora de recommender), por cada 1.000 se cobran valores adicionales (ej. $0.0833 a hoy para 1000 recomendaciones para 100.000 usuarios)
Recomendaciones finales
Para no incurrir en costos inesperados:
Una vez finalizado el ejercicio mencionado en este artículo?
- Recuerda borrar los archivos de datos subidos y eliminar el Bucket de S3
- Elimina los recommenders que no uses como sus datgaset groups y sus datasets.
En caso que desees pausar y continuar en otro momento, te recomiendo presionar el botón "Stop recommender" que pausara el billing y el entrenamiento del Recommender hasta que vuelvas lo reactives.
Una vez detenido para reactivarlo hay que ingresar al recommender y presionar "Start Recommender"